If your data distribution shifts, use self-learning
University of Tübingen
tl;dr: Test-time adaptation with self-learning improves robustness of large-scale computer vision models on ImageNet-C, -R, and -A.
News
| November '22 | The paper was accepted for publication in the Transactions of Machine Learning Research (TMLR). The reviews and our comments are published on OpenReview. |
| July '22 | We presented the ImageNet-D dataset at the ICML 2023 Shift Happens Workshop! The dataset is now part of the Shift Happens Benchmark. |
| May '21 | We released a first reference implementation of robust pseudo-labeling. Stay tuned for the full code release. |
| April '21 | The first pre-print, titled "Adapting ImageNet-scale models to complex distribution shifts with self-learning" is now available on arXiv: arxiv.org/abs/2104.12928. |
| April '21 | A preliminary version of the paper with the title "Better adaptation to distribution shifts with Robust Pseudo-Labeling" was selected for a contributed talk at the ICLR Workshop on Weakly Supervised Learning. |
Abstract
We demonstrate that self-learning techniques like entropy minimization and pseudo-labeling are simple and effective at improving performance of a deployed computer vision model under systematic domain shifts. We conduct a wide range of large-scale experiments and show consistent improvements irrespective of the model architecture, the pre-training technique or the type of distribution shift. At the same time, self-learning is simple to use in practice because it does not require knowledge or access to the original training data or scheme, is robust to hyperparameter choices, is straight-forward to implement and requires only a few adaptation epochs. This makes self-learning techniques highly attractive for any practitioner who applies machine learning algorithms in the real world. We present state-of-the-art adaptation results on CIFAR10-C (8.5% error), ImageNet-C (22.0% mCE), ImageNet-R (17.4% error) and ImageNet-A (14.8% error), theoretically study the dynamics of self-supervised adaptation methods and propose a new classification dataset (ImageNet-D) which is challenging even with adaptation.
 Robust pseudo labeling (RPL) achieves a new state of the art on ImageNet-C, ImageNet-A and ImageNet-P across various model architectures.
Robust pseudo labeling (RPL) achieves a new state of the art on ImageNet-C, ImageNet-A and ImageNet-P across various model architectures.
Contributions
- We obtain state-of-the-art adaptation performance on all common robustness datasets (IN-C: 22.0% mCE, IN-A: 14.8% top-1 error, IN-R: 17.4% top-1 error) and improve upon existing strategies for increasing model robustness for all tested model types.
- We find that self-learning with short update intervals and a limited number of both adaptable and distributed parameters is crucial for success. We leverage label noise robustness methods to enable adaptation with hard labels and a limited number of images, a problem not typically present in smaller scale domain adaptation.
- Given the huge performance boost on all robustness datasets, we re-purpose the closest candidate to an ImageNet-scale domain adaptation dataset---the dataset used in the Visual Domain Adaptation Challenge 2019---and propose a subset of it as an additional robustness benchmark for the robustness community. We refer to it as ImageNet-D.
Key Experiments
 Model selection is done on the four dev corruptions in ImageNet-C (left). We use the resulting hyperparameters to evaluate models on the ImageNet-C test set, ImageNet-A and ImageNet-R.
Model selection is done on the four dev corruptions in ImageNet-C (left). We use the resulting hyperparameters to evaluate models on the ImageNet-C test set, ImageNet-A and ImageNet-R.
 mCE (lower is better) ImageNet-C in %.
Entropy minimization (ENT) and pseudo-labeling paired with a robust loss function (RPL) reduce the mean Corruption Error (mCE) on IN-C for different models. We report the dev score on the holdout corruptions that were used for hyper-parameter tuning and the "test" score on the 15 test corruptions, evaluated with the best hyper-parameters found on the dev set. We compare vanilla trained (Baseline) and the best known robust variants of different architectures.
*) For the EfficientNet-L2 model, we evaluate the mCE on dev on the severities [1,3,5] to save computational resources. For the ResNet50 model, we show results averaged over three seeds as "mean (unbiased std)".
mCE (lower is better) ImageNet-C in %.
Entropy minimization (ENT) and pseudo-labeling paired with a robust loss function (RPL) reduce the mean Corruption Error (mCE) on IN-C for different models. We report the dev score on the holdout corruptions that were used for hyper-parameter tuning and the "test" score on the 15 test corruptions, evaluated with the best hyper-parameters found on the dev set. We compare vanilla trained (Baseline) and the best known robust variants of different architectures.
*) For the EfficientNet-L2 model, we evaluate the mCE on dev on the severities [1,3,5] to save computational resources. For the ResNet50 model, we show results averaged over three seeds as "mean (unbiased std)".
ImageNet-D: A new challenging robustness benchmark
We propose a subset of the dataset from the Visual Domain Adaptation Challenge 2019 as an additional robustness benchmark. We only consider the subset of the original dataset whose classes can be mapped to ImageNet classes to enable an off-the-shelf evaluation of ImageNet trained models.
 Overview of six domains in ImageNet-D. The dataset is a filtered version of the VisDa dataset common in domain adaptation research.
To make the dataset easy to use in a context similar to other robustness datasets, we filtered and remapped the original VisDa dataset onto ImageNet labels.
Overview of six domains in ImageNet-D. The dataset is a filtered version of the VisDa dataset common in domain adaptation research.
To make the dataset easy to use in a context similar to other robustness datasets, we filtered and remapped the original VisDa dataset onto ImageNet labels.
Our best model — the Noisy Student EfficientNet-L2 model — performs considerably worse on this dataset compared to the other robustness benchmarks, making this dataset an interesting future benchmark for the robustness community!
Implementation
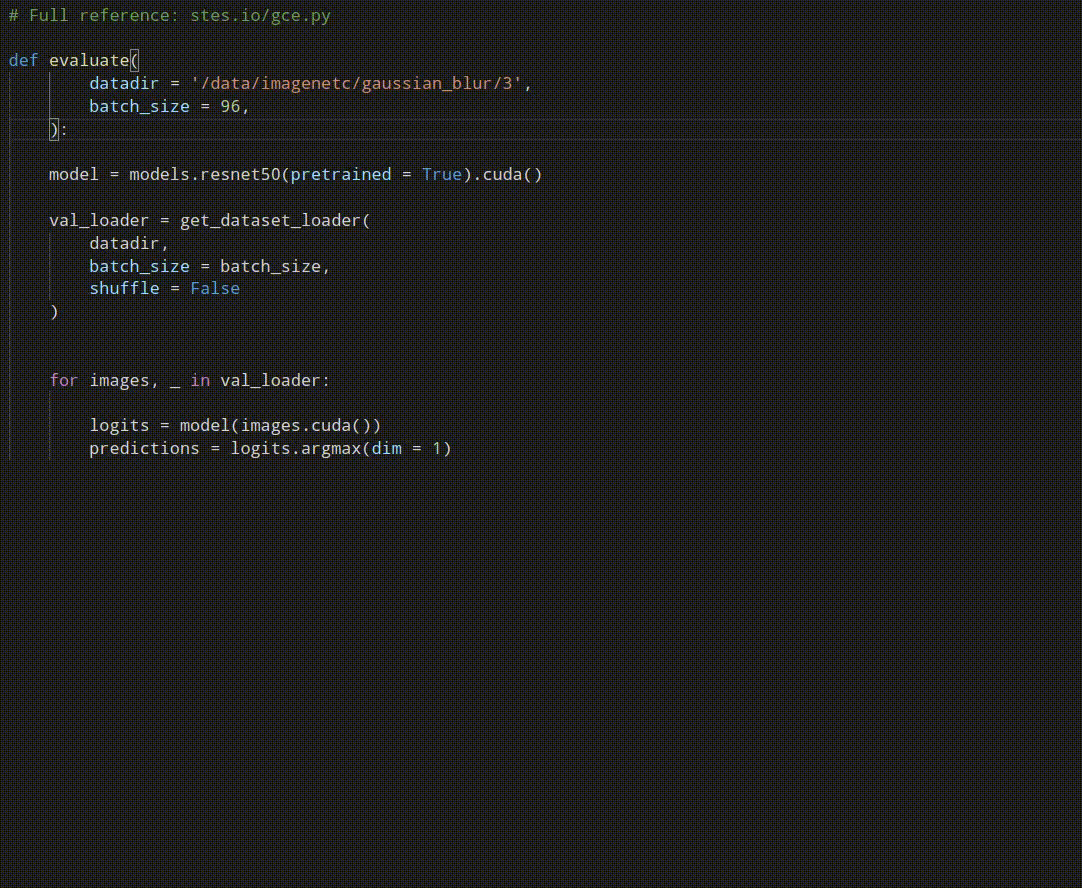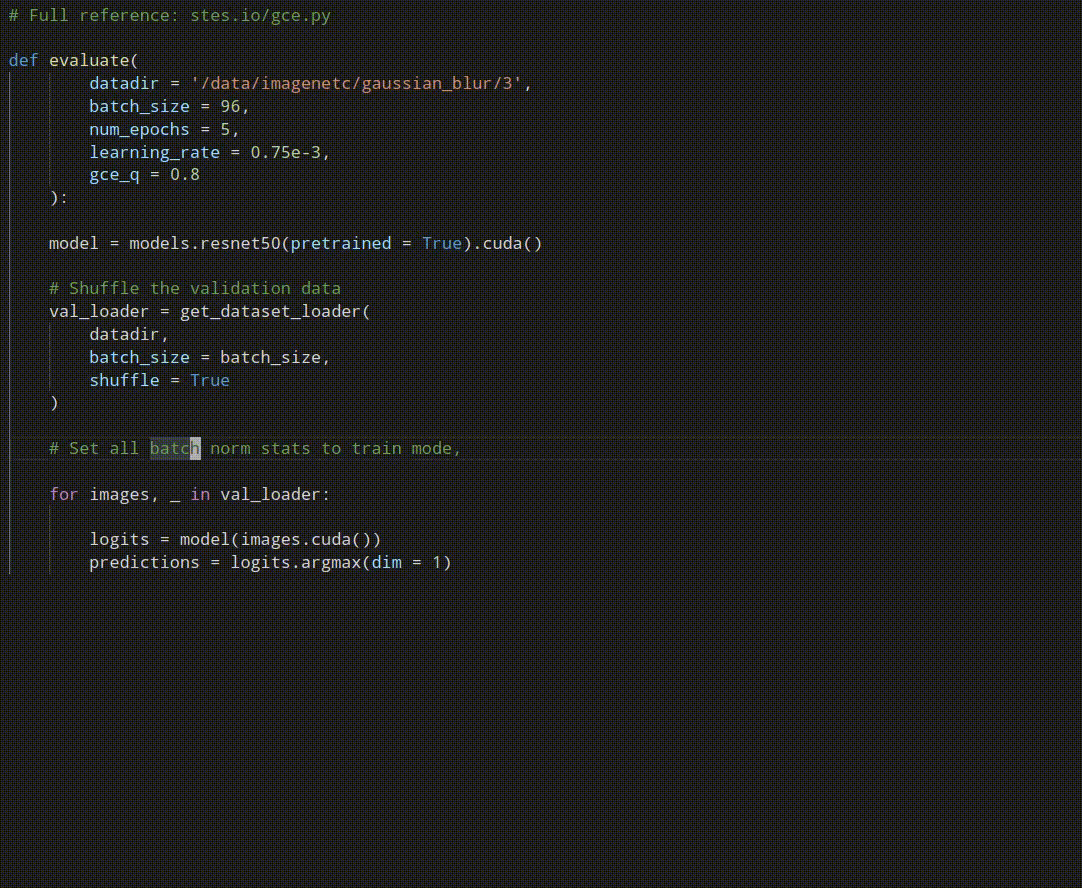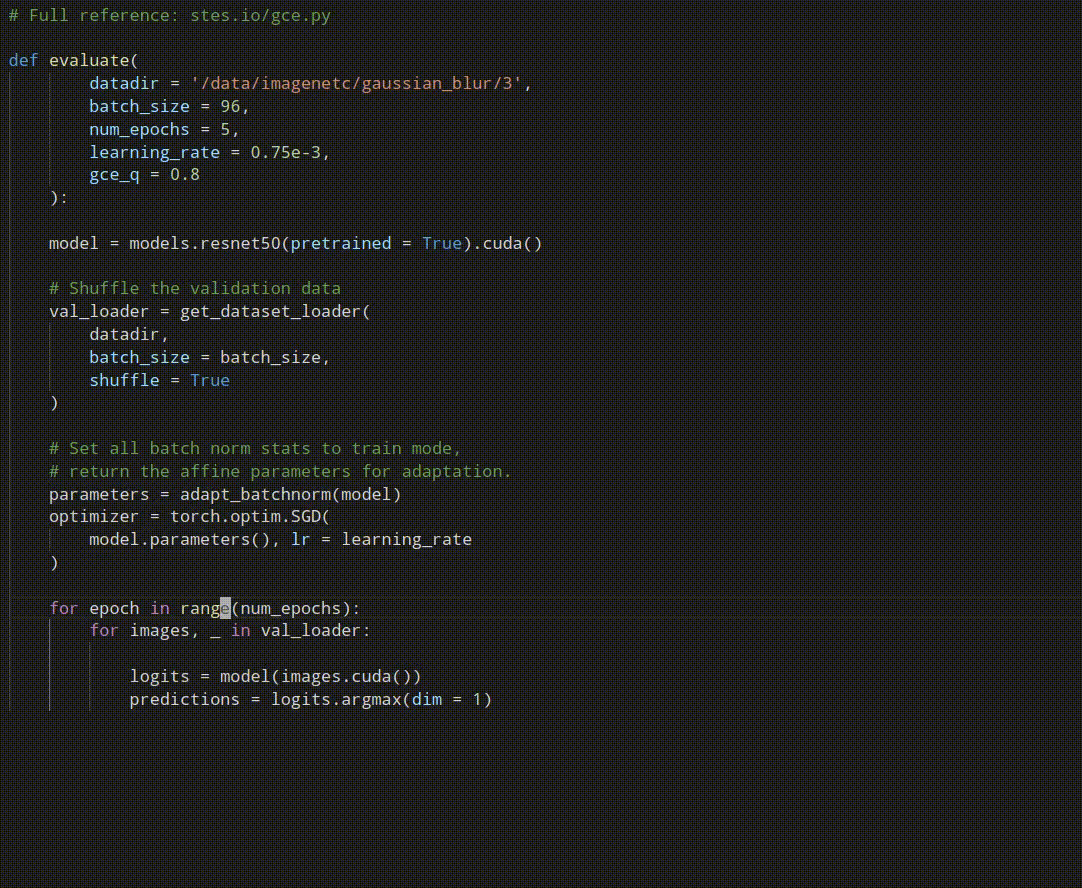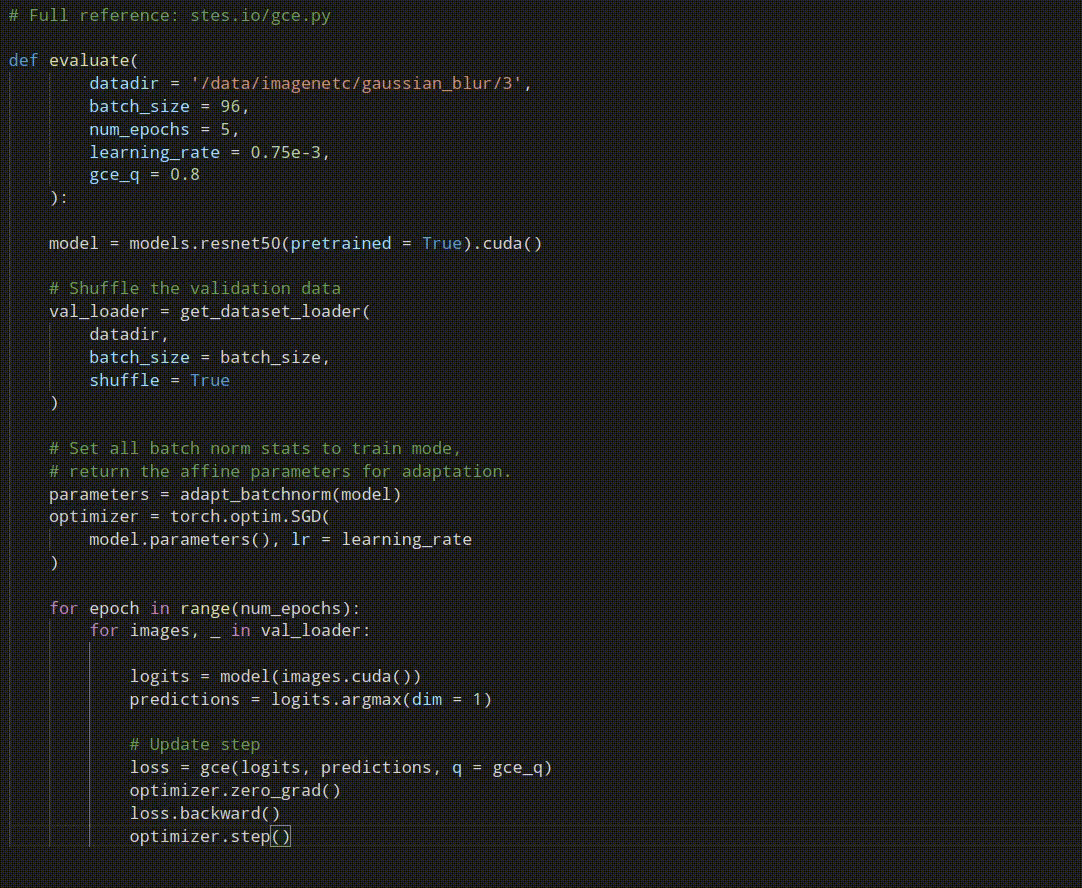
Robust pseudo-labeling is conceptually easy to implement. Notably, the best performing variant does not require to cache any values and computes the pseudo-labels on the fly. Have a look at our reference implementation.
BibTeX
If you find our analysis helpful, please cite our pre-print:
author = {
Rusak, Evgenia. and
Schneider, Steffen and
Pachitariu, George and
Eck, Luisa and
Gehler, Peter and
Bringmann, Oliver and
Brendel, Wieland and
Bethge, Matthias
},
title = {
If your data distribution shifts,
use self-learning
},
journal={
Transactions of Machine Learning Research
},
year={2022},
url={https://openreview.net/forum?id=vqRzLv6POg},
}
Notes
- Concurrent to this work, the CLIP model from Radford et al. [2103.00020] has shown to be effective at various robustness datasets. In particular, zero shot transfer to ImageNet-R is at 11.1% (vs. 17.4% for our best adapted model). On ImageNet-A, we still slightly outperform CLIP: 22.9% vs. 16.5% for the non-adapted Efficient Net model and 14.8% for an adapted EfficientNet model. Given the impressive performance on the ImageNet sketch dataset, it is conceivable that CLIP will also get good performance on ImageNet-D.