Improving robustness against common corruptions by covariate shift adaptation
LMU Munich
University of Tübingen
tl;dr: We propose to go beyond the assumption of a single sample from the target domain when evaluating robustness. Re-computing BatchNorm statistics is a simple baseline algorithm for improving the corruption error up to 14% points over a wide range of models, when access to more than a single sample is possible.
News
- September '20: Our paper was accepted for poster presentation at NeurIPS 2020. We will update the arXiv version accordingly. Stay tuned for the code release.
- July '20: A shorter workshop version of the paper was accepted for oral presentation at the Uncertainty & Robustness in Deep Learning Workshop at ICML 2020.
- June '20: The pre-print is available on arXiv: arxiv.org/abs/2006.16971.pdf
Abstract
Today's state-of-the-art machine vision models are vulnerable to image corruptions like blurring or compression artefacts, limiting their performance in many real-world applications. We here argue that popular benchmarks to measure model robustness against common corruptions (like ImageNet-C) underestimate model robustness in many (but not all) application scenarios. The key insight is that in many scenarios, multiple unlabeled examples of the corruptions are available and can be used for unsupervised online adaptation. Replacing the activation statistics estimated by batch normalization on the training set with the statistics of the corrupted images consistently improves the robustness across 25 different popular computer vision models. Using the corrected statistics, ResNet-50 reaches 62.2% mCE on ImageNet-C compared to 76.7% without adaptation. With the more robust AugMix model, we improve the state of the art from 56.5% mCE to 51.0% mCE. Even adapting to a single sample improves robustness for the ResNet-50 and AugMix models, and 32 samples are sufficient to improve the current state of the art for a ResNet-50 architecture. We argue that results with adapted statistics should be included whenever reporting scores in corruption benchmarks and other out-of-distribution generalization settings.
Method
Batch Normalization statistics are typically estimated on the training dataset. Under covariate shift in the inputs (e.g., by adding image corruptions), these statistics are no longer valid. We investigate improvements of various computer vision models when estimating statistics on the test dataset. To cover settings with small sample sizes \(n\) on the target domain, we optionally combine source and target statistics using \(N\) pseudo-samples from the source domain. This yields the following corrected normalization statistics:
$$ \bar{\mu} = \frac{N \mu_s}{N + n} + \frac{n \mu_t}{N + n} , \quad \bar{\sigma}^2 = \frac{N \sigma_s^2}{N + n} + \frac{n \sigma_t^2}{N + n} . $$
Dataset
We consider ImageNet-C comprised of 15 test and 4 holdout corruptions as the main dataset in our study. We run ablations on IN-V2, IN-A and ObjectNet and will consider recently released datasets in updates of our pre-print. Gains are only to be expected on dataset with a clearly defined and systematic domain shifts, such as in ImageNet-C. On other datasets, more powerful domain adaptation methods are likely needed to correct the shift.
Key Results
Adaptation boosts robustness of a vanilla trained ResNet-50 model
We found that the robustness of computer vision models based on the ResNet-50 architecture is currently underestimated and can be substantially improved if access to more than one target sample is allowed. When employing the corrected statistics to normalize the network, we see performance improvements of as much as 14% points mCE.
The exact value depends on the target domain batchsize and the source domain pseudo-batchsize. The following plot shows the dependency of performance on IN-C and number of unlabeled target domain samples we can access, for the best pseudo-batchsize \(N\) selected on the holdout set existing for this purpose (solid lines), or the default \(N = 0\) (dashed line).
Adaptation consistently improves corruption robustness across IN trained models
We benchmarked the improvement of model robustness for all computer vision architectures implemented in the torchvision library. We find consistent improvements, typically on the order of 10% points, when using the proposed adaptation scheme.
Adaptation yields new state of the art on IN-C for robust models.
Besides vanilla trained ResNets, we also explore a variety of robust models part of the IN-C Leaderboard. We see considerable improvement across all of these models for a sufficient number of samples from the target domain.
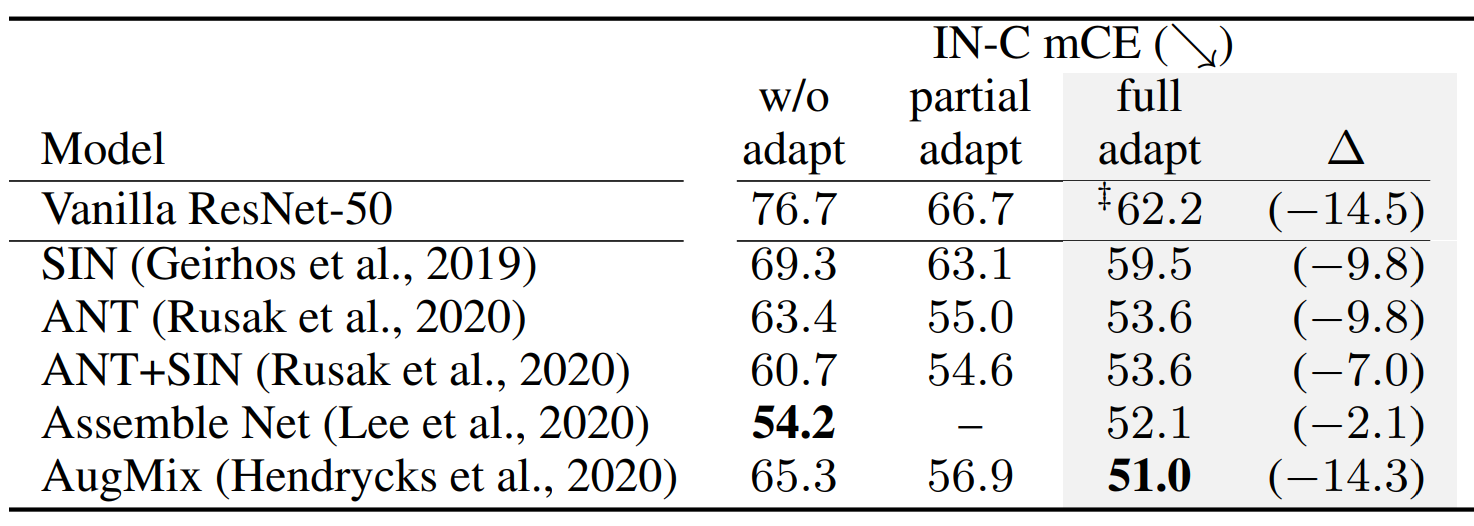
In the following, we investigate the result in more detail and show results for different pseudo batchsizes (color) and target dataset sizes (x axis). We provide a theoretical model qualitatively explaining the observed behavior in the paper.
Additional Results
Please have a look at our pre-print for further results. We will also soon release code for reproducing our experiments. Please reach out if you have any additional questions.
BibTeX
If you find our analysis helpful, please cite our pre-print:
author = { Schneider, Steffen and Rusak, Evgenia
and Eck, Luisa and Bringmann, Oliver
and Brendel, Wieland and Bethge, Matthias
},
title = {Removing covariate shift improves
robustness against common corruptions
},
journal = {CoRR},
volume = {abs/2006.16971},
year = {2020},
}